1.3
Strojové učení – úvod
Strojové učení (ML – machine learning) je jednou z nejvýznamnějších oblastí umělé inteligence, která v posledních letech zaznamenala rychlý pokrok. Zatímco umělá inteligence zahrnuje širokou škálu technologií zaměřených na napodobování lidské inteligence, strojové učení se konkrétně zaměřuje na to, aby se strojům umožnilo učit se z dat a v průběhu času zlepšovat svůj výkon bez explicitního programování. V této kapitole si rozebereme, co je strojové učení, jak funguje a jaké jsou jeho klíčové aplikace v dnešním světě.
1.3.1
Co je strojové učení?
Strojové učení je podmnožinou umělé inteligence, která umožňuje počítačům učit se ze zkušeností. Algoritmy strojového učení místo toho, aby byly explicitně naprogramovány k provádění určitého úkolu, používají velké množství dat k identifikaci vzorců a k vytváření předpovědí nebo rozhodnutí na základě těchto vzorců. Tento proces umožňuje strojům v průběhu času zlepšovat svou přesnost a efektivitu, a to, jakmile získají přístup k většímu množství dat.
Strojové učení ve své podstatě zahrnuje trénování modelu s využitím historických dat, což modelu umožňuje vytvářet předpovědi nebo rozhodovat se při zobrazení nových dat. Tato schopnost „učit se“ z dat bez lidského zásahu činí strojové učení neuvěřitelně výkonným, zejména v oblastech, kde jsou k dispozici velké datové sady.
1.3.2
Typy strojového učení
Existují tři hlavní typy strojového učení, každý s vlastním přístupem k tomu, jak učení probíhá:
- Učení pod dohledem. V případě učení pod dohledem je model trénován na označených datech, což znamená, že každý trénovací příklad má známý výstup. Model se učí mapovat vstupy na správný výstup. Například v modelu učení pod dohledem používaném pro rozpoznávání obrázků je algoritmus trénován pomocí obrázků označených jako „kočka“ nebo „pes“. Po trénování dokáže model identifikovat, zda nový obrázek obsahuje kočku nebo psa.
+
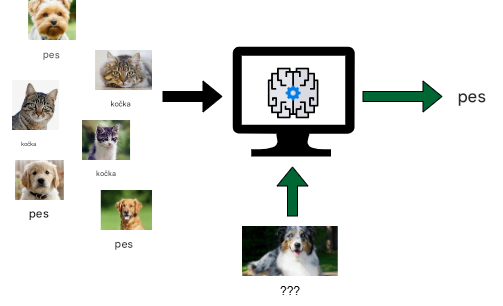
Obr. 3. Ilustrace učení pod dohledem.
- Učení bez dohledu. Učení bez dohledu zahrnuje trénování modelu na datech, která nemají žádné popisky. Cílem je, aby model našel v datech skryté vzorce nebo struktury. Běžnou aplikací je shlukování, kde algoritmus seskupuje podobné datové body bez předem definovaných kategorií. Učení bez dohledu lze například použít ke seskupení zákazníků s podobným nákupním chováním pro cílený marketing.
+
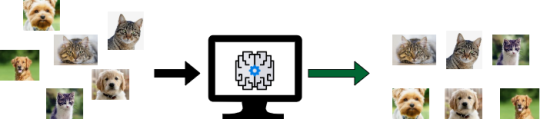
Obr. 4. Ilustrace učení bez dohledu.
- Učení založené na principu zpevňování (Reinforcement Learning). Při tomto způsobu učení se model učí metodou pokusů a omylů tím, že přijímá zpětnou vazbu ze svého prostředí. Tento typ učení se často používá při hraní her a robotice. Model provádí akce v daném prostředí a za každou akci obdrží odměnu nebo penalizaci. Postupem času se naučí provádět akce, které maximalizují odměny. Známým příkladem je AlphaGo – umělá inteligence, která se naučila hrát, a nakonec i porazila lidské šampiony ve hře Go.
©
Tento obrázek nemůže být z licenčních důvodů začleněn přímo do materiálu. Na obrázek se můžete podívat ZDE.
Obr. 5. Ilustrace zpevňovacího učení [13].
1.3.3
Jak funguje strojové učení
Strojové učení obvykle probíhá podle strukturovaného procesu, který převádí data do prediktivního modelu:
- Sběr dat. Stejně jako umělá inteligence obecně vyžaduje strojové učení obrovské množství dat. Tato data mohou sestávat z obrázků, textu nebo číselných hodnot v závislosti na problému, který je třeba řešit.
- Trénování modelu. Dalším krokem je vložení těchto dat do algoritmu strojového učení, který je použije k identifikaci vzorců. Trénovací proces zahrnuje úpravu parametrů modelu pro optimalizaci jeho předpovědí.
- Testování a vyhodnocení. Jakmile je model natrénován, je testován na samostatné datové sadě, aby se vyhodnotilo, jak dobře dokáže vytvářet predikce na základě nových, dosud neznámých dat. Výkon modelu se měří pomocí metrik, jako je přesnost, preciznost nebo úplnost.
- Nasazení. Po trénování a testování je model nasazen v reálných provozních podmínkách, aby mohl začít vytvářet predikce nebo rozhodovat. Model se poté s rostoucím počtem dat dále učí a vylepšuje.
1.3.4
Aplikace strojového učení
Strojové učení (ML) již způsobuje revoluci v mnoha odvětvích tím, že umožňuje lepší predikce a zlepšuje rozhodovací proces. Některé běžné aplikace jsou uvedeny v tabulce 3.
Tab. 3. Aplikace strojového učení.
1.3.5
Výzvy ve strojovém učení
Navzdory rychlému pokroku čelí strojové učení několika výzvám. Jedním z nejpalčivějších problémů je kvalita dat. Modely strojového učení jsou jen tak dobré, jako data, na kterých jsou trénovány. Nekvalitní nebo zkreslená data mohou vést k nepřesným předpovědím a nezamýšleným důsledkům.
Další výzvou je princip „černé skříňky“ některých modelů strojového učení, zejména modelů hlubokého učení. Tyto modely mohou být tak složité, že ani vývojáři nemusí plně chápat, jak model činí určitá rozhodnutí, což vyvolává obavy o transparentnost a odpovědnost.
Konečně, výpočetní zdroje jsou limitujícím faktorem. Trénování rozsáhlých modelů strojového učení vyžaduje značný výpočetní výkon a úložiště, které nemusí být snadno dostupné pro všechny organizace.
Souhrn
Strojové učení je výkonná podmnožina umělé inteligence, která umožňuje počítačům učit se z dat a zlepšovat svůj výkon bez explicitního programování. Tato schopnost zpracovávat a analyzovat obrovské množství informací vedla k řadě inovací v různých oblastech od zdravotnictví po finance. Vzhledem k neustálému vývoji a zdokonalování technologií strojového učení je nezbytné řešit výzvy v oblasti kvality dat, transparentnosti modelů a výpočetních zdrojů, abychom uvolnili plný potenciál této transformační technologie.
Která z následujících vět nejlépe popisuje základní myšlenku strojového učení?
Který z následujících příkladů nejlépe ilustruje neřízené učení?
Který z těchto kroků je obvykle poslední fází životního cyklu modelu strojového učení?
Ve kterém odvětví je nejpravděpodobnější přímé uplatnění posilovacího učení?
Který z následujících problémů je nejvíce spojen s povahou „černé skříňky“ některých modelů strojového učení?